1. Introduction
- 뉴스를 크롤링하여 주요 문장을 추출하여 요약
- Maximal Marginal Relvance(MMR)을 사용한 unsupervised extractive summarization 구현
- pretrained sentence transformer를 사용하여 sentence embedding 추출
2. Maximal Marginal Relevance
- <The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries>에서 제안된 방법
- Marginal relevance: query와의 relevance가 높고, 이미 선택한 sentence와의 중복도가 낮은 sentence 선택
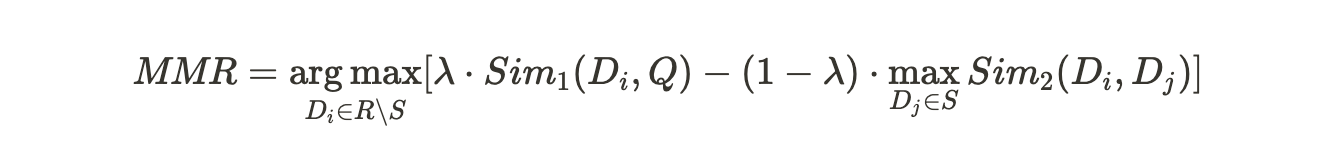
3. Code
- load_model
- 불필요한 모델 로딩을 방지하기 위해 cache 적용
- read_article
- newsplease를 사용하여 뉴스 크롤링
- clean_text
- kiwi tokenizer를 사용한 문장 분리
- 이메일, url 제거
- encode
- 문장 임베딩 추출
- jhgan/ko-sroberta-multitask 사용
- maximal_marginal_relevance
- 뉴스 제목을 query로, 문장을 candidate로 사용
모듈
import re
import functools
from kiwipiepy import Kiwi
from newsplease import NewsPlease
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
@functools.cache
def load_model(
model_name: str,
):
print('loading model...')
kiwi = Kiwi()
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
_ = model.eval().requires_grad_(False)
return kiwi, tokenizer, model
def read_article(
url: str
):
article = NewsPlease.from_url(url)
title = article.title
text = article.maintext
return title, text
def clean_text(
text: str
):
text = text.replace('\n', ' ')
text = re.sub(r'\bhttps?://\S+\b', ' ', text)
text = re.sub(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b', ' ', text)
text = text.strip()
return text
def preprocess(text: str, kiwi: Kiwi):
sents = [s.text for s in kiwi.split_into_sents(text)]
sents = [clean_text(s) for s in sents]
return sents
def mean_pooling(
token_embeddings: torch.Tensor, # (N, S, D)
attention_mask: torch.Tensor # (N, S)
):
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def encode(model, tokenizer, texts, batch_size=8, max_length=256):
device = model.device
embeds = []
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
inputs = tokenizer(batch_texts, truncation=True, padding=True, max_length=max_length, return_tensors='pt').to(device)
outputs = model(**inputs)
batch_embeds = mean_pooling(outputs.last_hidden_state, inputs.attention_mask)
embeds.append(batch_embeds.cpu())
embeds = torch.cat(embeds, dim=0)
embeds = F.normalize(embeds, dim=1)
return embeds
def maximal_marginal_relevance(
query_embeds: torch.Tensor, # (D)
candidate_embeds: torch.Tensor, # (N, D)
k: int = 3,
_lambda: float = 0.3,
sort: bool = True,
):
num_candidates = candidate_embeds.size(0)
lefted = list(range(num_candidates))
selected = []
while len(selected) < k:
query_score = query_embeds @ candidate_embeds[lefted].T
if len(selected) == 0:
_idx = torch.argmax(query_score).item()
else:
dupl_score = candidate_embeds[selected] @ candidate_embeds[lefted].T
dupl_score = dupl_score.max(dim=0).values
_idx = torch.argmax(_lambda * query_score - (1 - _lambda) * dupl_score)
idx = lefted.pop(_idx)
selected.append(idx)
if sort:
selected = sorted(selected)
return selected
def summarize(url, model_name='jhgan/ko-sroberta-multitask', device='cuda'):
kiwi, tokenizer, model = load_model(model_name)
model.to(device)
title, text = read_article(url)
sents = preprocess(text, kiwi)
query_embeds = encode(model, tokenizer, [title])[0]
context_embeds = encode(model, tokenizer, sents)
selected = maximal_marginal_relevance(query_embeds, context_embeds, k=3, _lambda=0.6)
summary = '\n'.join([sents[i] for i in selected])
return {
'title': title,
'text': text,
'url': url,
'summary': summary
}실행 코드
url = 'https://n.news.naver.com/mnews/article/215/0001111260?sid=101'
results = summarize(url)
print(results['summary'])4. Results
# https://n.news.naver.com/mnews/article/215/0001111260?sid=101
삼성전자 파운드리 포럼 개최삼성전자가 오늘 오후 서울 코엑스에서 삼성 파운드리 포럼을 개최합니다.
삼성전자 파운드리사업부 최시영 사장이 기조연설에 나설 예정으로, AI반도체에 최적화된 GAA 트랜지스터 기술 등 인공지능 기술 패러다임의 변화를 이야기할 예정입니다.
특히 범LG가의 LX세미콘이 이번 강연에 나서는 것은 두 회사의 강화된 협력관계를 보여주는 것은 물론, 파운드리 반도체 생태계 강화와 공급망 다변화라는 '윈-윈' 전략이 될 것이란 전망입니다.# https://n.news.naver.com/mnews/article/277/0005281385?sid=105
SK스퀘어와 CJ ENM이 토종 온라인동영상서비스(OTT) 웨이브와 티빙의 합병 작업에 돌입했다.
웨이브와 티빙의 합병설은 2020년 7월 나왔다.
합병하면 웨이브와 티빙의 MAU가 900만명이 넘는다.'ai' 카테고리의 다른 글
| VIsual LAyout(VILA) 모델로 논문 PDF 파일에서 구조를 추출하는 방법 (1) | 2023.07.15 |
|---|---|
| BERTScore Knowledge Distillation (0) | 2023.07.06 |
| Hydra + Lightning Fabric으로 딥러닝 학습 template 만들기 (0) | 2023.05.18 |
| 꼬맨틀 풀이 프로그램 개발 (0) | 2023.05.17 |
| Transformer BERT Fine-tuning: Named Entity Recognition (0) | 2023.05.16 |


